Data Engineering Concept And Docker
Data Enginnering Basic Concept
Information sourced from an IBM article, which is a helpful resource for understanding data pipelines.
What is data pipeline and why we need it?
A data pipeline is a way of handling raw data from different sources, moving it to a data storage location like a data lake or data warehouse for analysis. Before the data goes into storage, it typically undergoes processing, which includes tasks like filtering, masking, and aggregations. These processes ensure that the data integrates properly and follows standardized formats. This becomes crucial, especially when the data is meant for a relational database, which has a specific structure requiring alignment of data columns and types for updating existing data with new information.
As the name implies, data pipelines act like conduits for data science projects or business intelligence dashboards. Data can come from various sources like APIs, SQL and NoSQL databases, and files, but this data usually isn't immediately usable. Data scientists or engineers typically handle data preparation tasks, organizing the data to meet the specific needs of the business use case. Well-structured data pipelines form the basis for a variety of data projects, including exploratory data analyses, data visualizations, and machine learning tasks.
Types of data pipelines
- Batch Processing: Batch processing involves loading “batches” of data into a repository at set time intervals. It’s suitable when there isn’t an immediate need to analyze a specific dataset (e.g., monthly accounting). It is more associated with the ETL (extract, transform, load) data integration process.
- Streaming Data: Streaming data is used when data needs to be **continuously** updated. Actions are grouped together as a “topic” or “stream” and transported through messaging systems or brokers, such as Apache Kafka. Streaming processing systems have lower latency than batch systems but may not be as reliable due to the possibility of unintentionally dropped messages or extended queue times.
Data Pipeline Architecture
- Data Ingestion: Data is collected from various sources, including different data structures. While businesses can choose to extract data only when ready to process it, it’s often better to first land the raw data within a cloud data warehouse provider.
- Data Transformation: A series of jobs are executed to process data into the required format for the destination data repository.
- Data Storage: The transformed data is then stored within a data repository, making it accessible to various stakeholders.
Docker Basic Concept
Information sourced from an IBM article, which is a helpful resource for understanding docker.
What is Docker?
Docker is an open source platform that enables developers to build, deploy, run, update and manage containers—standardized, executable components that combine application source code with the operating system (OS) libraries and dependencies required to run that code in any environment.
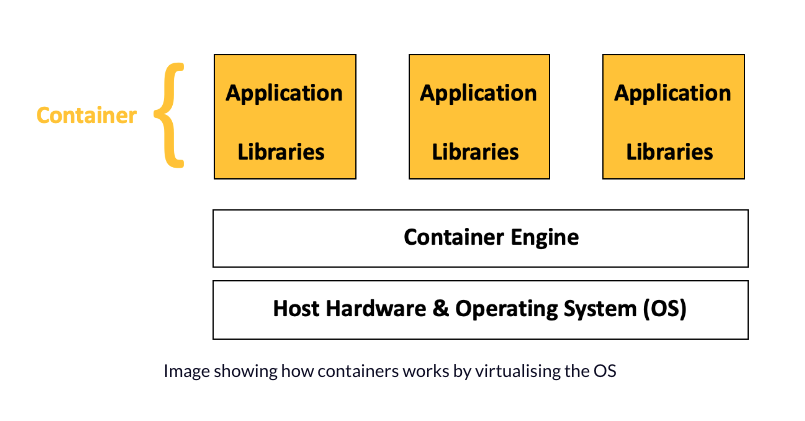
Containers are executable units of software in which application code is packaged along with its libraries and dependencies, in common ways so that the code can be run anywhere—whether it be on desktop, traditional IT or the cloud.
How containers work, and why they are so popular?
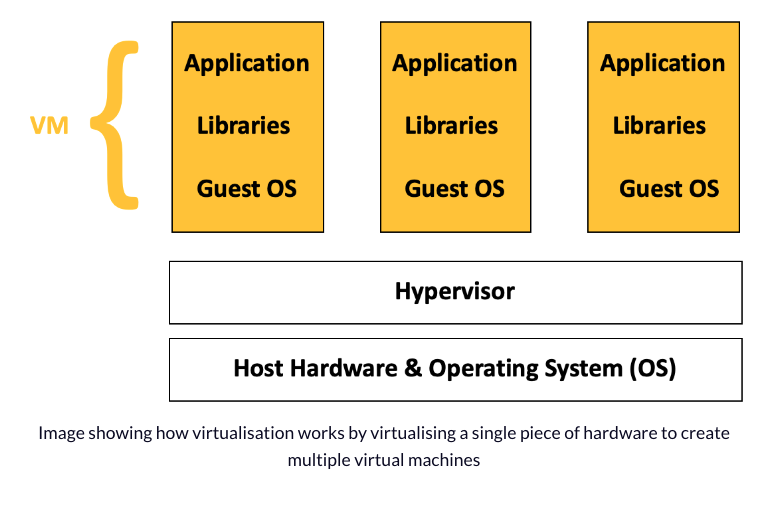
Containers are made possible by special features in the Linux kernel that enable process **isolation** and **virtualization**. These features, such as control groups (Cgroups) for managing resources and namespaces for restricting access to system areas, allow different parts of an application to use the resources of a single instance of the operating system . This is similar to how a hypervisor lets multiple virtual machines (VMs) share a server’s CPU, memory, and other resources.
Container technology provides the benefits of VMs, like isolating applications, cost-effective scalability, and disposability, along with some extra advantages:
- Lighter weight: Unlike VMs, containers don't carry the entire operating system and hypervisor. They only include the necessary processes and dependencies for running the code. Containers are smaller in size (measured in megabytes, compared to gigabytes for some VMs), use hardware more efficiently, and start up faster.
- Improved developer productivity: Applications in containers can be written once and run anywhere. Containers are faster and easier to deploy, provision, and restart compared to VMs. This makes them suitable for use in continuous integration and continuous delivery (CI/CD) pipelines, and they align well with Agile and DevOps practices.
- CI (Continuous Integration): Continuous integration is a way of developing software where developers regularly combine the new code they’ve written into the existing codebase. They do this more often during the development cycle, making sure to add the new code at least once every day.
- CD (continuous delivery): Continuous delivery allows development teams to automate the process of moving software through the different stages of its development lifecycle.
- Greater resource efficiency: Containers allow developers to run more copies of an application on the same hardware compared to VMs, leading to cost savings in cloud usage.
(Image from FreeCodeCamp)
(Image from FreeCodeCamp)
Why use Docker?
Docker is a tool that helps make and handle containers.
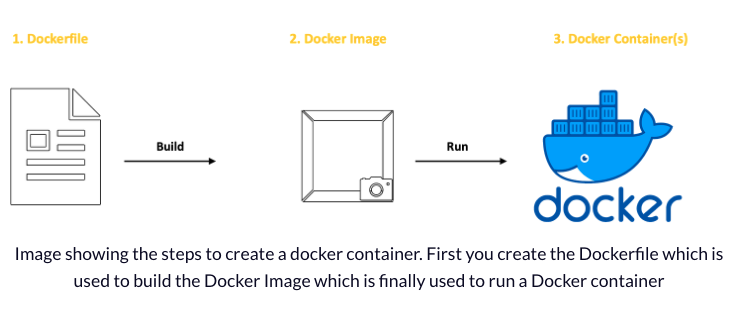
In simple terms, Docker has two main ideas to grasp: the Dockerfile and Docker Images.
A Dockerfile holds the steps to construct a Docker Image.
A Docker Image acts like a blueprint for making Docker containers. It includes all the needed code, tools, libraries, and settings to run a software application.
In summary, a Dockerfile is employed to construct a Docker Image, and then that Docker Image is used as the guide to create one or more Docker containers.
(Image from FreeCodeCamp)
Docker deployment and orchestration
Docker plugins: Docker plugins are like add-ons that enhance Docker's capabilities. The Docker Engine plugin system comes with several built-in plugins, and you can also add extra plugins from other sources.
Docker Compose: Docker Compose is a tool that developers employ to handle applications with multiple containers, all operating on the same Docker host. It works by generating a YAML (.YML) file outlining the services in the application and then deploying and running containers effortlessly with a single command.
Kubernetes: Kubernetes is a free, open-source platform for managing container orchestration, originating from a project initially used by Google. It takes care of important tasks in handling architectures based on containers, such as deploying containers, updates, finding services, setting up storage, balancing the workload, monitoring health, and more.